
Download ImageNet Images by WordNet ID
Download ImageNet images for Transfer Learning, with ImageNet-Utils
From this earlier post we learnt to easily train a specialized image classification model with Transfer Learning without writing a single line of code. With the help of the retrain script provided by the Google Codelab Tensorflow for Poets, all we need is a directory structure containing directories of training images like this:
|- my-training-images/
|- daisy/
|- some-image-1.jpg
|- some-image-2.jpg
|- some-image-3.jpg
|- dandelion/
|- some-image-4.jpg
|- some-image-5.jpg
|- some-image-6.jpg
|- roses/
|- some-image-7.jpg
|- some-image-8.jpg
|- some-image-9.jpg
|- sunflowers/
|- some-image-10.jpg
|- some-image-11.jpg
|- some-image-12.jpg
|- tulip/
|- some-image-13.jpg
|- some-image-14.jpg
|- some-image-15.jpg
In summary:
- each sub-directory takes the name of the training image label (e.g. daisy)
- within the sub-directory, we store the training images belong to that class. It doesn’t matter how we name these images as long as the images are stored within that folder.
ImageNet Intro
Say we’d like to obtain some training images of different types of mushrooms, one way to get these images is via ImageNet. Here is the official description of the site:
ImageNet is an image database organized according to the WordNet hierarchy (currently only the nouns), in which each node of the hierarchy is depicted by hundreds and thousands of images. Currently we have an average of over five hundred images per node. We hope ImageNet will become a useful resource for researchers, educators, students and all of you who share our passion for pictures.
Each image category is represented in the form of WordNet ID, also known as wnid.
Lookup Category and WNID
For starter, go to the ImageNet website.
Search for an image category that we want. Say, fly agaric (a type of mushroom).
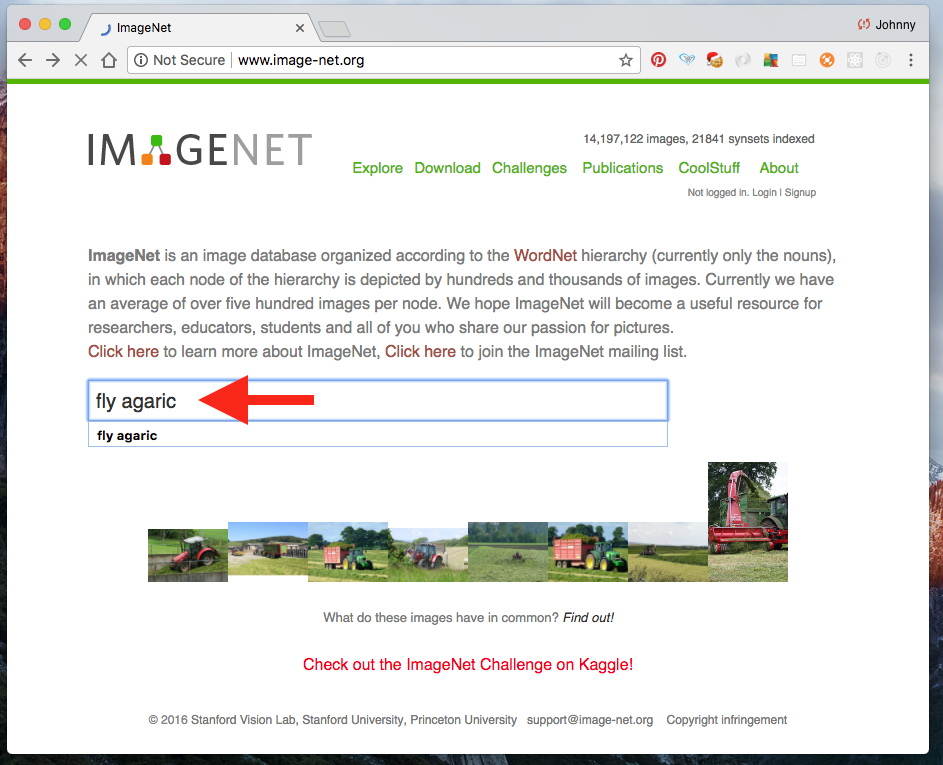
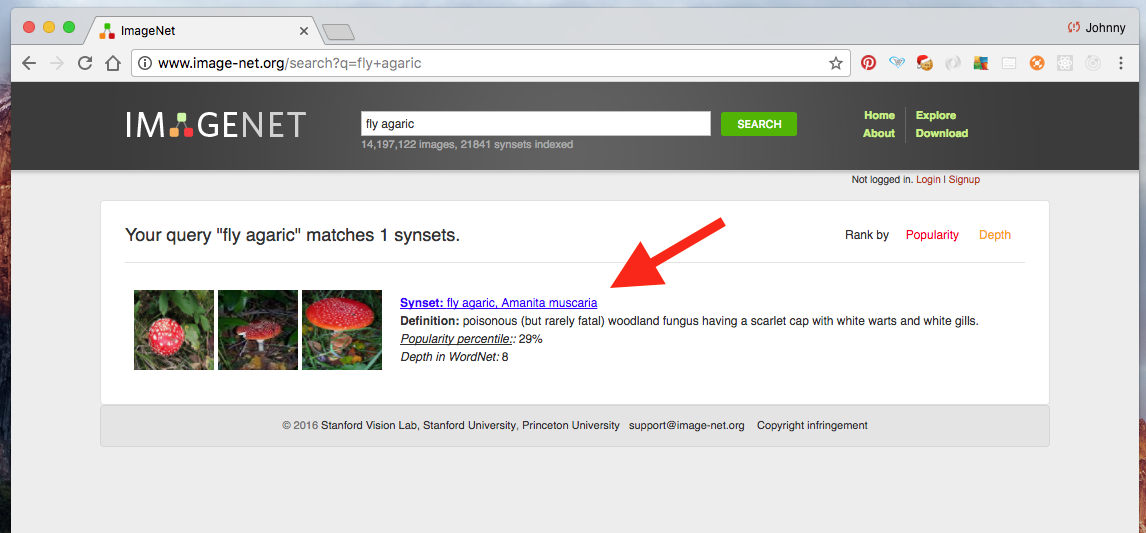
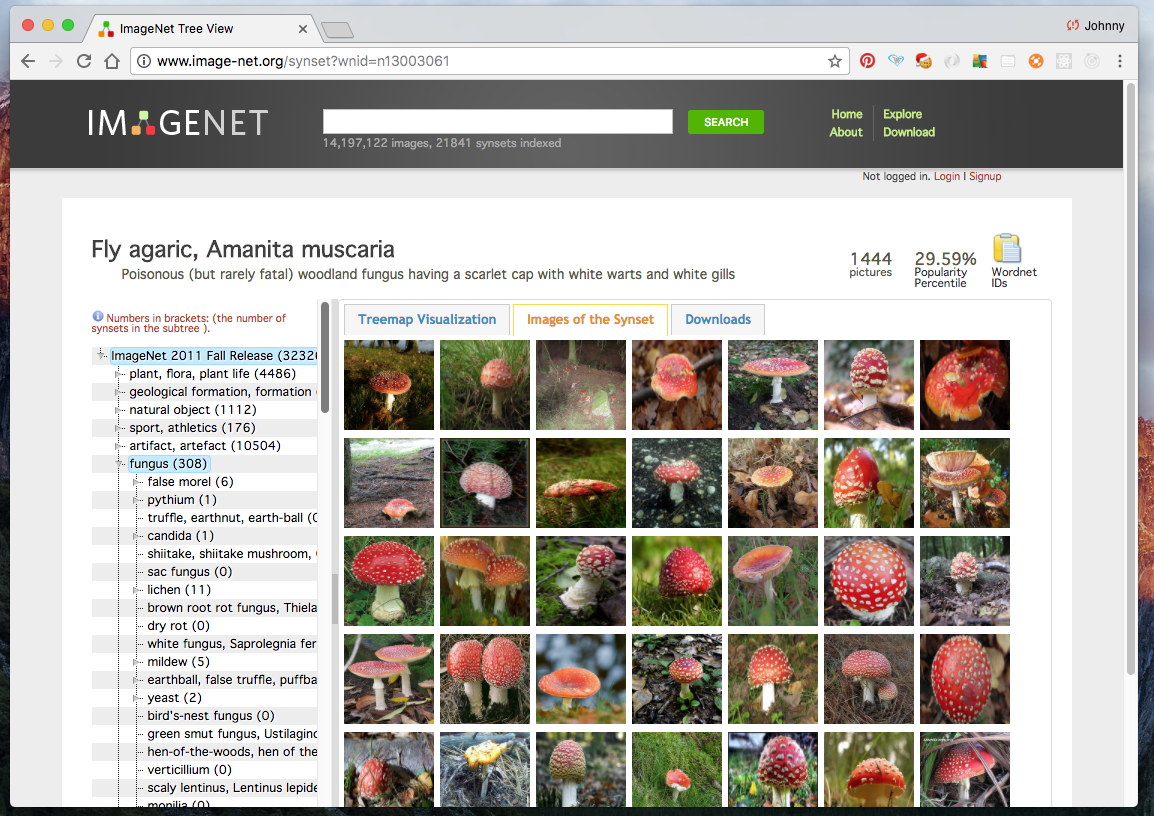
Some observations:
- we should see is a grid of Fly agaric images.
- we should see the WNID of this category, from the URL: http://www.image-net.org/synset?wnid=n13003061
Now, if we scoll down along the hierarchy bar on the left, we should eventually see our fly agaric (note the nested structure).
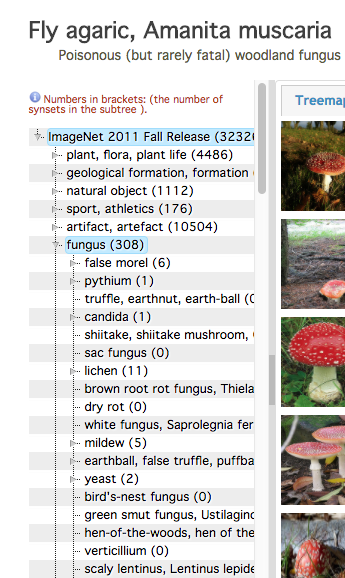


Note above that our fly agaric is highlighted in blue in the scroll bar.
Let’s return to the main screen:
Click on the Treemap Visualization tab:
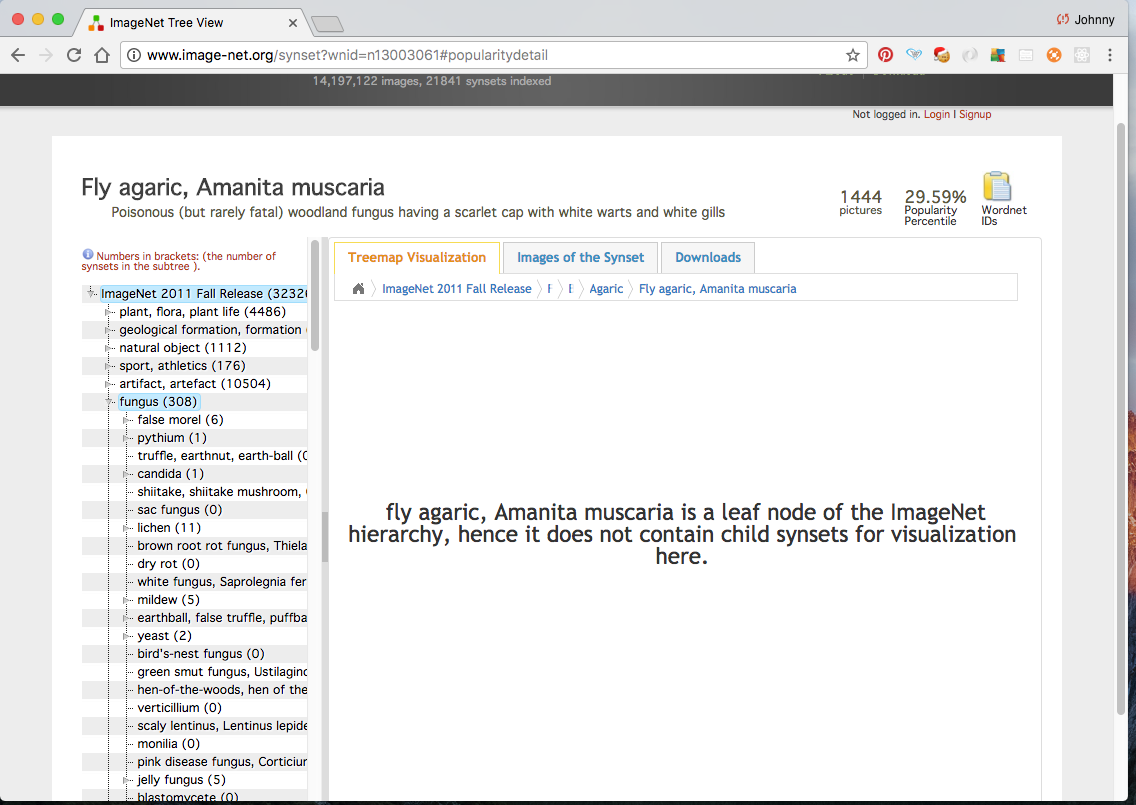
The above snapshot tells us that fly agaric is a leaf node. i.e. there are no sub categories underneath this node. If we click on the icon on the top right, it will copy one WNID (n13003061) to the clipboard. (if however the category is not a leaf node clicking the icon will copy all the immediate child WNIDs underneath it as well. But that is another story to tell.)
Now, if we click the Downloads tab, we may find the list of image URLs associated with this WNID:
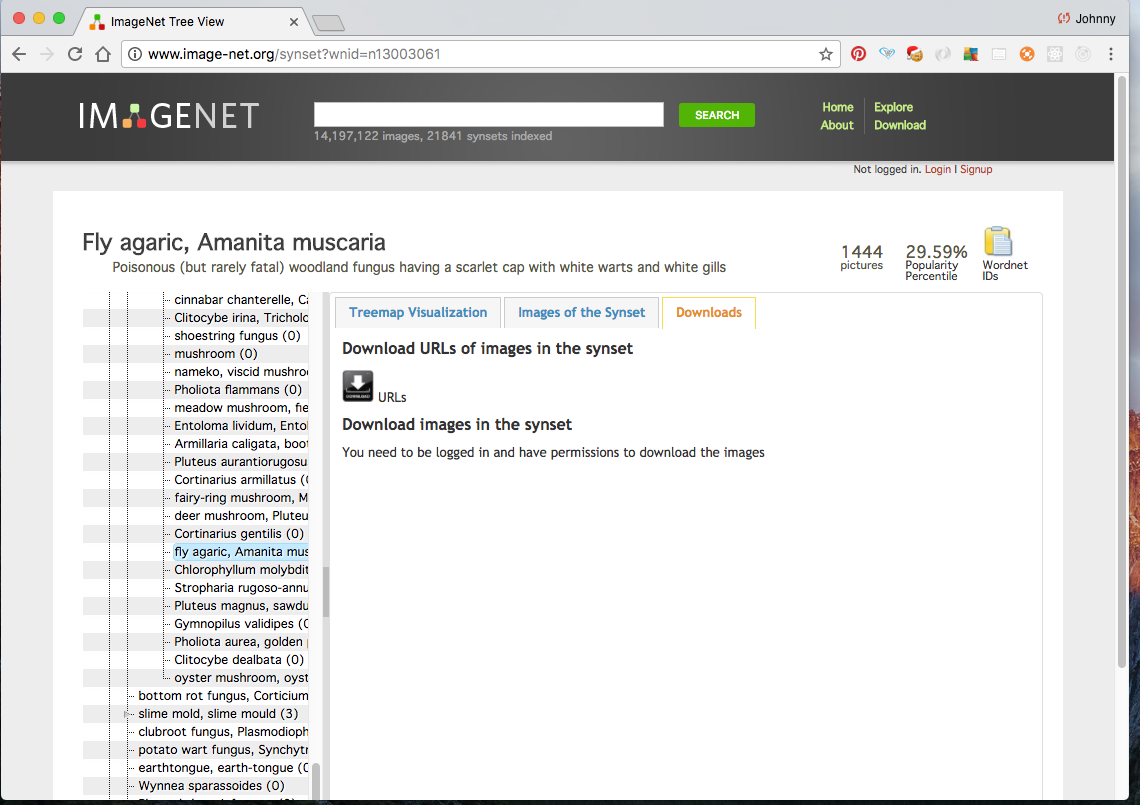
Click the URLs button will review the list of URLs. Note the API in address bar: http://www.image-net.org/api/text/imagenet.synset.geturls?wnid=n13003061.
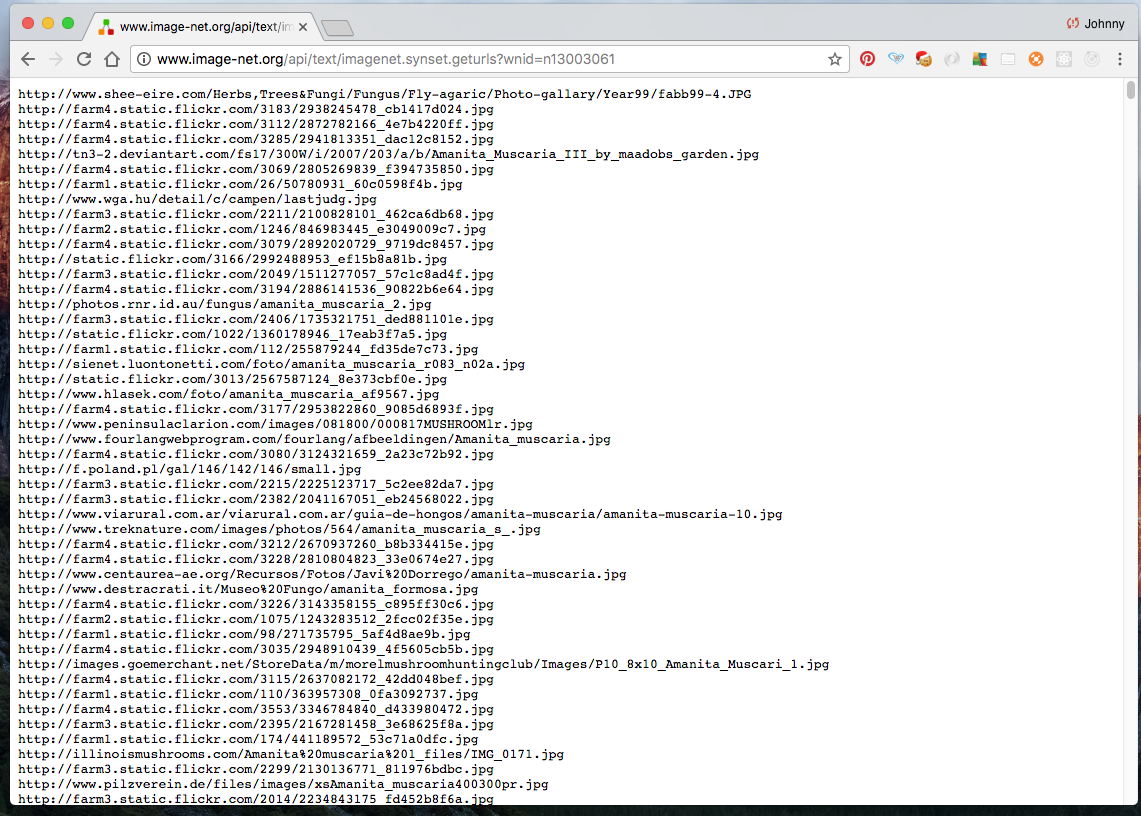
This API is handy. Basically, by providing the API a wnid, it returns the list of image URLs associated with that wnid. If we copy a handful of URLs and paste it in a browser, we can see for ourselves the images are indeed fly agaric. Warning: ImageNet is not perfect. There could be errors (hopefully small portion only). It’s constantly improving with its internal validation system.
Download Imagenet Images by WNID
Now we know how to resolve wnid from a name (e.g. fly agaric) via the ImageNet website, we can download the images for a desired wnid with the help of this very handy tool called ImageNet_Utils, an open sourced tool published on Github developed by tzutalin. Follow the instructions to download images.
Here are the steps that I follow to download images for fly agaric (wnid = n13003061):
- git clone the repository:
$ git clone https://github.com/tzutalin/ImageNet_Utils - navigate into the repository:
$ cd ImageNet_Utils - the script seems to work well with Python 2.7 (and not so for Python 3.x). So let’s create an Anaconda python environment (feel free to use Python 3.x if you like. I used Python 3.6 originally and bumped into errors. So guessing the scripts aren’t Python 3.x compatible yet - maybe):
$ conda create py27p13 python=2.7.13 - activate the conda environment (so we have Python 2.7 enabled in an isolated environment):
(py27p13) $ source activate py27p13 - do a one-liner command:
(py27p13) $ ./downloadutils.py --downloadImages --wnid n13003061 - this will start the download. Note that there may be errors / anomalies - which I will describe later.
- the images will be saved to the repository:
./n13003061/n13003061_urlimages/ - (at a later stage) move the entire image folder to somewhere else. Restructure it to make it suitable for our transfer learning exercise.
For example, move to somewhere else and restructure the directory like this:
|- my-training-images/
|- n13003061_fly_agaric
|- image-1.jpg
|- image-2.jpg
|- etc...
Limitation of ImageNet Image Download
So far I’ve come across some small anomalies / limitations of downloading images from ImageNet via URLs. This is not a significant general problems, thought it would be worth mentioning here.
Broken URL
Say the URL is no longer valid, we may get errors like this during download (just some examples I’ve seen).
HTTP Error 403: Forbidden
HTTP Error 404: Not Found
Fail to download
<urlopen error [Errno 51] Network is unreachable>
The download script will simply print the error and move on to the next URL, and so on.
Flickr dummy image
When an image no longer exists on Flickr (where some images are stored), you will see a dummy image that looks like this:

You will see quite a number of this. The strategy is to either remove them manually (by eye), or find a programmatic way to remove these later on.
Update 2017-12-13: I just noticed image like this has a file size of about 2 KB. Most good images have a size of a least 40 KB. A quick win could be to do a sort by file size in the Mac finder window, and filter away the very small images, such as this.
Corrupted Image
The download process is not perfect. Sometimes an image could be partially downloaded. For instance, when I click on one of this partially downloaded images, it just loads forever (or shows sign of errors). Such as this one:
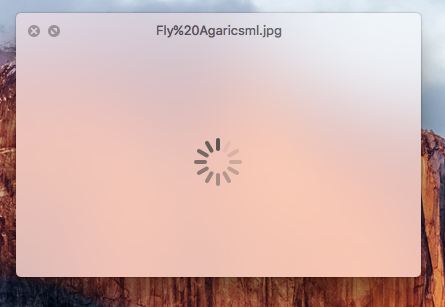
These images then to have really small file size, of less than 2 KB (as far as I could see).
A quick win is probably to just filter out files like this. Only when have the time we then attempt download again in future.
Non Image Type
You’d also notice some files downloaded are not actually images (.jpg, .png, etc), but text files (e.g. .php, .html, .txt, etc).
This is probably due to some URLs are no longer valid and the server decided to respond with a text file instead of an image.
This can be filtered away easily by file type. (do a sort in Mac finder, or programmatically using filename extension).
Summary
In this article we have:
- define our objective: to have a directory structure for storing training images, for performing transfer learning - as required by this earlier post, or Google Codelab Tensorflow for Poets.
- introduce ImageNet: how to resolve WordNet ID (
wnid) given an image category name, and use the API to get the image URLs associated with the selectedwnid. - introduce ImageNet_Utils, a handy tool to ease the ImageNet image download process. This downloads the images via URLs.
Next steps:
- repeat the process above, and download training images per mushroom category (e.g. fly agaric, common stinkhorn, scarlet elf cup, etc.)
- split the downloaded images into 3 sets: training, validation, and test. From the readme of ImageNet_Utils, the tool appears to have the feature to accomplish this too.
